1. single sample t-test : 하나의 변수가 특정 값과 같은지 확인하는 방법, stata에서 사용하는 command는 (ttest 변수==특정 값)
2. paired ttest : 한 집단이 경험한 두 가지의 사실을 비교할 때 사용, stata command로는 (ttest 수학==과학)
3. independent group ttest: 두 집단이 경험한 한 가지 사실이 있을 때 그 두 집단 간의 평균을 비교
ttest를 시작하기 전에 주의할 것은, 비교를 하게 될 집단의 속성이 평균에서 동일하게 떨어져 있는가의 여부인데요. 각 집단이 매우 다른 수준으로 평균에서 흩어져 있다면, 두 집단의 특성이 다르기 때문에 평균을 비교하는게 어려울 수 있겠죠.
따라서 우리는 ttest를 하기 전에 두 집단 간의 등분산 검정을 한답니다. 우리가 살펴보려는 종속변수에 대한 각 집단의 분산이 동일한지를 보는 것이죠. 이때 사용하는 통계 방법이 레빈 테스트에요. (levene's test)
레빈 테스트의 통계량이 유의 확률인 0.05보다 크다면 각 집단의 분산은 같다고 할 수 있어요. 하지만, 통계량이 유의 확률인 0.05보다 작다면 등분산이 성립하지 않기 때문에 우리는 ttest 대신에 welch's test를 사용해야 된답니다.
stata에서 레빈 테스트를 진행하는 command는 다음과 같아요. robvar 변수, by(group), 여기에서 차이를 보려는 변수명이 'ct_e'이고, group이 남/여, 즉 Gender라고 했을 때, 사용하는 command는 robvar ct_e, by(Gender)라고 할 수 있겠죠.

그럼 이런 결과를 얻게 되는데요. W0는 평균에서의 레빈 테스트이고, W50은 중앙값으로부터의 레빈 테스트, W10은 평균값에서 10%에 해당하는 값들을 사용한 레빈 테스트입니다. 지금 보이는 결과값은 모두 p-value가 0.05보다 작기 때문에 우린 각 집단의 등분산이 성립하지 않는다고 할 수 있어요. 따라서 이 경우엔 ttest가 아닌 welch’s test 또는 unequal 옵션을 사용할 수 있답니다. 그럼 이런 테이블을 얻게 돼요. stata command는 ttest ct_e, by(Gender) welch랍니다.
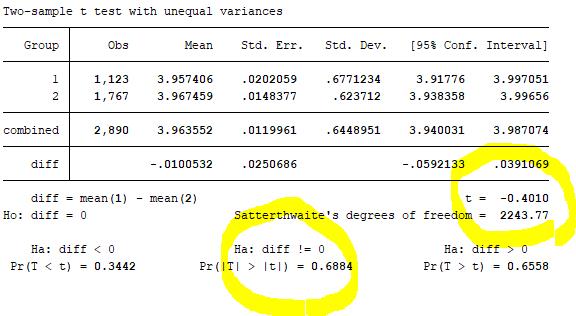
이 테이블로부터의 결과값은 t 값과 유의 확률을 통해 해석할 수 있는데, 이 표에 의하면 t 값은 –0.4010이고 p-value는 0.69로, 유의 확률이 0.05보다 크기 때문에 분산이 다른 두 집단(Gender)의 ct_e 평균 차이는 통계적으로 유의하지 않다는 결론을 얻게 된답니다.
'◆ 일상 > ◆ 일상-통계 공부하기' 카테고리의 다른 글
| 종속변수 로그화 하는 이유 (0) | 2024.02.20 |
|---|---|
| [펌] 다중공선성 해결 방법 (0) | 2024.02.19 |
| 변수를 바꿔가면서 반복적으로 회귀분석할 수 있는 명령어 (0) | 2024.02.13 |
| coursera 강의 - Data Visualization in R with ggplot2 (2) | 2024.02.08 |
| (Co선생님) 기초통계 가중치 주는 법 (0) | 2024.02.07 |